
本论文主要作者来自小红书 AIGC 团队(Dynamic-X-Lab),Dynamic‑X‑LAB 是一个专注于 AIGC 领域的研究团队,致力于推动姿态驱动的人像生成与视频动画技术。他们以高质量、高可控性的生成模型为核心,围绕文生图(t2i)、图像生成(i2i)、图像转视频(i2v)和风格迁移加速等方向展开研究,并通过完整的开源方案分享给开发者与研究者社区。
基于一致性模型(Consistency Models, CMs)的轨迹蒸馏(Trajectory Distillation)为加速扩散模型提供了一个有效框架,通过减少推理步骤来提升效率。然而,现有的一致性模型在风格化任务中会削弱风格相似性,并损害美学质量 —— 尤其是在处理从部分加噪输入开始去噪的图像到图像(image-to-image)或视频到视频(video-to-video)变换任务时问题尤为明显。
这一核心问题源于当前方法要求学生模型的概率流常微分方程(PF-ODE)轨迹在初始步骤与其不完美的教师模型对齐。这种仅限初始步骤对齐的策略无法保证整个轨迹的一致性,从而影响了生成结果的整体质量。
为了解决这一问题,文章提出了单轨迹蒸馏(Single Trajectory Distillation,STD),一个从部分噪声状态出发的训练框架。
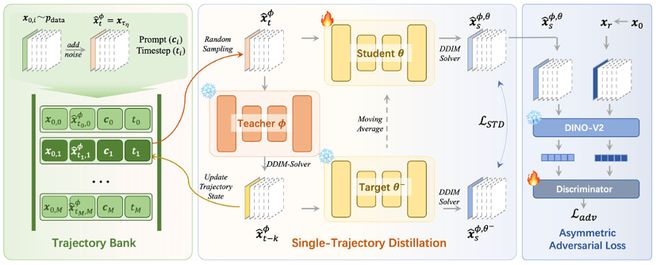
为了抵消 STD 引入的额外时间开销,文章设计了一个轨迹状态库(Trajectory Bank),预先存储教师模型 PF-ODE 轨迹中的中间状态,从而有效减轻学生模型训练时的计算负担。这一机制确保了 STD 在训练效率上可与传统一致性模型保持一致。
此外,该工作还引入了一个非对称对抗损失(Asymmetric Adversarial Loss),可显著增强生成结果的风格一致性和感知质量。
在图像与视频风格化任务上的大量实验证明,STD 在风格相似性和美学评估方面均优于现有的加速扩散模型。

STD 与其他方法的差异
如图 2 所示,(a) 中的传统一致性蒸馏方法(Other CMs)从 x_0 加噪得到不同的 x_t,再拟合多条 PF-ODE 轨迹的初始部分,存在轨迹不对齐问题。而在 (b) 中,文章提出的单轨迹蒸馏(Single-Trajectory Distillation, STD)方法则从一个固定的加噪状态 x_(τ_η ) 出发,通过教师模型完整地去噪出多个 x_t,并以此为训练目标,使学生模型在一条完整轨迹上实现自一致性。这种策略有效解决了训练 - 推理路径不一致的问题,提升了整体生成质量。
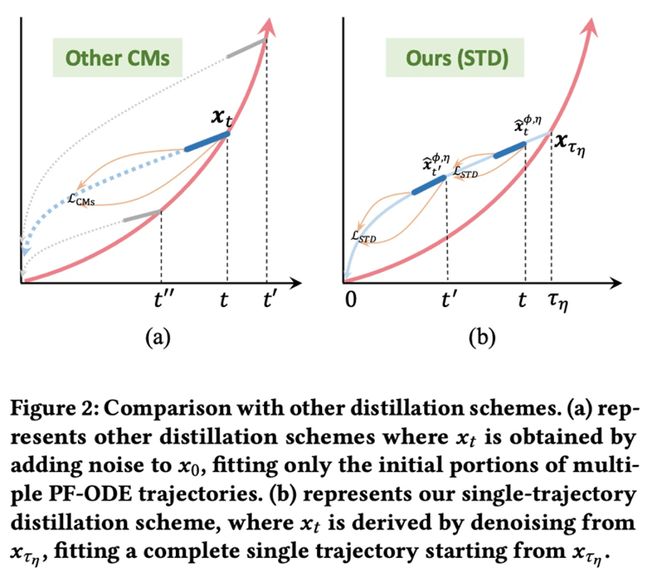
为了避免从 x_(τ_η ) 开始反复推理带来的训练开销,进一步提出了轨迹缓存库(trajectory bank),用于预存教师模型轨迹中的中间状态,从而保持训练效率不变。同时,引入了非对称对抗损失(asymmetric adversarial loss),对不同噪声级别下的生成图与真实图进行对比,有效提升图像饱和度,减少纹理噪声。
前置理论
【扩散模型】

【轨迹】

【基于部分加噪的编辑】

方法介绍
【单轨迹蒸馏理论】
在扩散模型中,理想情况下反向去噪轨迹应与前向扩散轨迹严格互逆。但实际中,不完美去噪模型会导致:

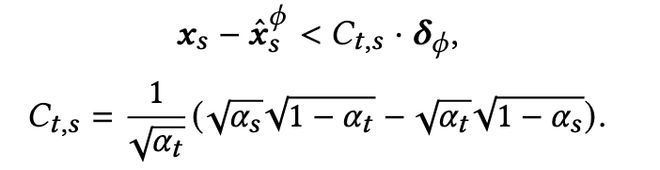
针对图像 / 视频风格化任务中固定起点 η 的需求,提出基于一致性模型仅在固定起点的单条轨迹上做一致性蒸馏,具体包含两个关键点:

根据第二部分对轨迹的定义,可以写出单轨迹蒸馏损失函数的表达式如下:
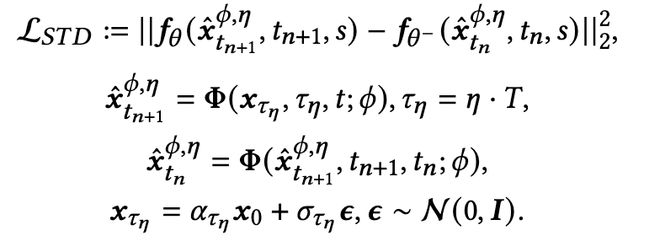
为降低蒸馏误差,约束学生模型学习的时间步 s 接近教师步 t:
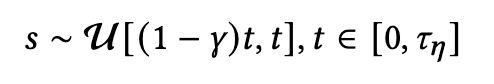
其中 γ 表示控制目标时间步 s 的取值下限比例因子通过缩短 t 与 s 的距离,可以减小误差上界,同时保留随机性提升模型性能。

【轨迹状态库】

【非对称对抗损失】

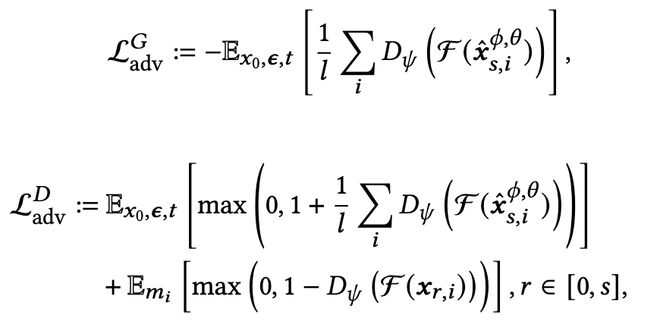
其中 F 表示 DINO-v2 模型,D_ψ 表示判别器,ψ 表示判别器的可学习参数,x_r 指对 x_0 加噪 r 步后获得的样本。

实验结果
【对比实验】

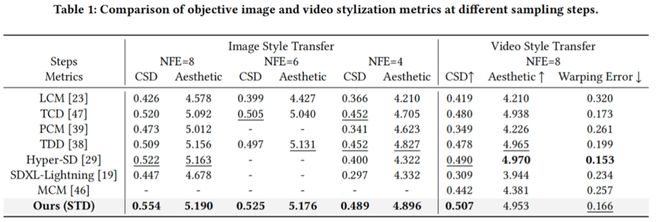
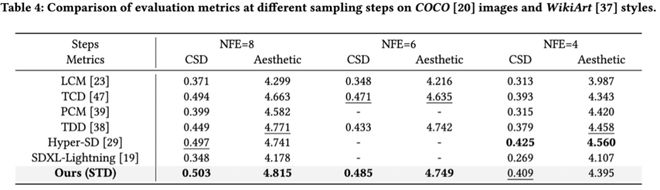
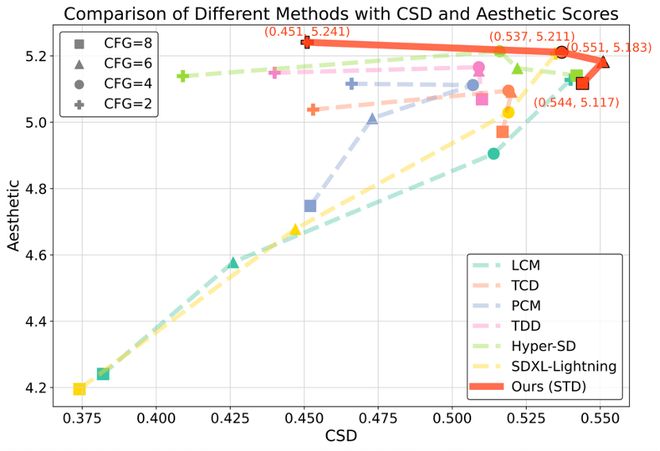
STD 与当前多种加速方法在 8 步、6 步、4 步下进行对比,在风格相似性和美学分数上达到 SOTA 水平。其中图像生成在 NFE=8 时 CSD 分数比 Hyper-SD 提升↑0.032;视频生成的 Warping Error 达到 0.166,显著优于 MCM 的 0.257。从可视化(图 4)中可以看出 STD 方法的风格质量和图像质量显著更高;在不同 CFG 的定量指标折线图中(图 5)也表现出了更优水平。
视频效果:
【消融实验】
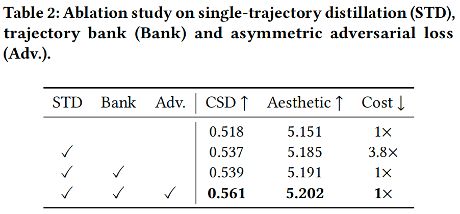
文章对单轨迹蒸馏方法、轨迹状态库以及非对称对抗损失函数做了消融实验(表 2),当使用轨迹状态库时,抵消了 STD 带来的额外 3.8 倍训练耗时,而 STD 方法和非对称对抗损失函数都显著提升了风格相似性分以及美学分。
其他重要参数的取值和特性消融实验:
STD 和非对称对抗损失强度(Fig 6):强度越大,细节和噪点越少,对比度越强,画质越好。

不同的噪声起点(Fig 8):η 越大,风格化程度越大,但是内容相关性越弱。

不同的目标时间步 s 的取值下限比例因子(Fig 10):更大的 γ 值带来更低噪声,更强的非对称对抗损失产生更高对比度;γ=0.7 在风格保持与细节呈现间取得最佳平衡。

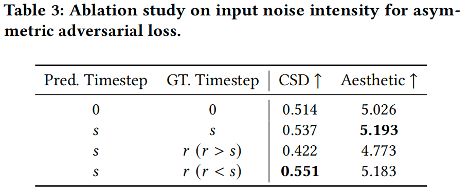
非对称对抗损失目标时间步位置(Table 3、Fig 9):当 r

【可扩展性试验】
文章进一步讨论了 STD 方法的适用范围,从 STD 的理论推导上看,该方法可用于其他任何 “基于部分噪声的图像 / 视频编辑” 任务,如 inpainting 等。为了验证猜想,文章展示了一组使用 STD 和其他加速方法用于 inpainting 的对比图。如图 7,相比 LCM 和 TCD 方法,STD 的 inpainting 效果更加自然。

结语
文章针对基于一致性模型的图像视频风格迁移加速方法,重点优化了风格相似性与美学质量。研究发现前向 SDE 轨迹中不同噪声强度会导致 PF-ODE 轨迹产生差异,据此提出基于特定噪声强度的单轨迹蒸馏方法(STD),有效解决了训练与推理轨迹不对齐问题。为降低 STD 方法的训练成本,创新性引入轨迹库机制,并采用非对称对抗损失提升生成质量。对比实验验证了本方法在风格保持与美学表现上的优越性,系统消融实验证实了各模块的有效性。该方法可扩展至部分噪声编辑任务,文章已探索了基于 STD 的图像修复应用,为后续相关工作提供新思路。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板