
在当前由大语言模型(LLM)驱动的技术范式中,检索增强生成(RAG)已成为提升模型知识能力与缓解「幻觉」的核心技术。然而,现有 RAG 系统在面对需多步逻辑推理任务时仍存在显著局限,具体挑战如下:
为建立严格的评估体系,学术界提出了 BRIGHT—— 首个面向推理密集型检索的权威测试集。该基准涵盖了源自经济学、心理学、数学及编程等多个知识密集型领域的真实查询。这些查询的共性在于其答案无法通过传统的直接检索显式获得,使得很多 RAG 系统失效。而 BRIGHT 必须通过多步推理构建证据链,也就是所谓的「第一性原理」, 从 「根源」 推导,而非 「类比」来解决问题。
针对这一技术挑战,蚂蚁集团 AQ-MedAI 团队提出了 DIVER(Deep reasonIng retrieVal and rERanking) 框架,旨在解决「推理密集型」(Reasoning-Intensive)场景下的信息检索难题。

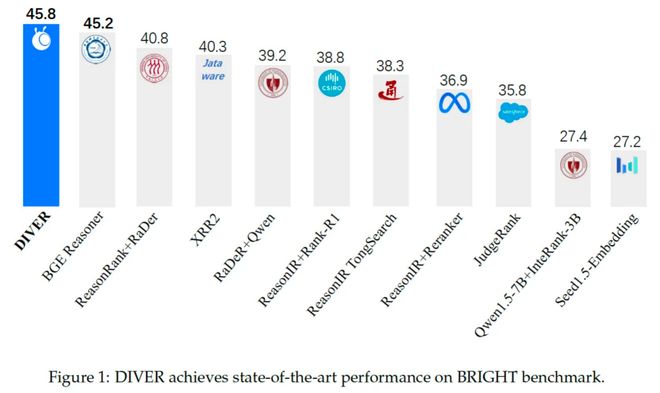
目前,DIVER 框架在 BRIGHT 公开排行榜上测评得分 45.8,排名第一,充分验证了其技术的领先性。
DIVER:推理驱动式检索系统
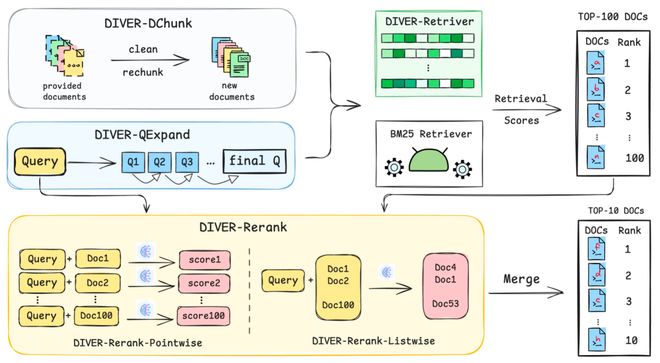
DIVER 是一套推理驱动式的检索框架,其将复杂的检索任务分解为四个阶段,主要为 DIVER-DChunk、DIVER-QExpand、DIVER-Retriever 和 DIVER-RERANK。
DIVER:技术架构深度拆解
第一阶段:文档预处理(DIVER-DChunk)—— 奠定坚实基础
高质量的知识库是有效检索的前提。DIVER 首先对原始文档进行「净化」和「重组」。它会自动清除文本中的噪声(如无关的 HTML 标签、格式错误),并利用语义理解技术将过长的文档智能切分为逻辑连贯、大小适中的「知识块」。
这一步确保了后续模型读取的是清晰、有序、高质量的信息,为后续的推理环节打下了坚实的基础。
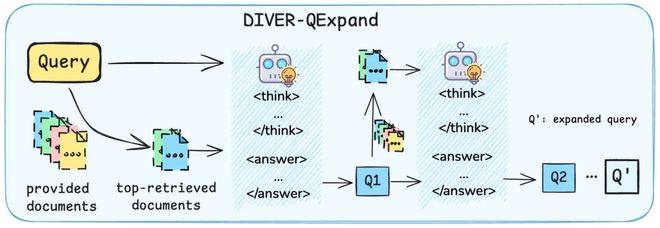
第二阶段:查询扩展(DIVER-QExpand)—— 让模型学会「追问」和「联想」
用户的原始问题可能不够精确,DIVER 采用了一种与文档「互动」的迭代式查询扩展策略。当接收到用户的初始查询后,系统并非立即进行检索,而是利用一个强大的语言模型对查询进行迭代式的「精炼」和「扩展」。模型会分析初始查询,并结合初步检索到的少量文档,生成更明确的推理路径和所需证据的描述,然后将这些信息补充回原始查询中。
这个过程会重复进行,形成一个反馈循环,使查询的意图越来越清晰、精准,引导系统走向正确的答案方向。
第三阶段:专为推理定制的检索(DIVER-Retriever)—— 从第一性出发,训练一位「侦探」,而非「图书管理员」
有了经过「思考」的查询,DIVER 会启用一个经过特殊训练的检索模型。这个模型的独特之处在于其训练数据:
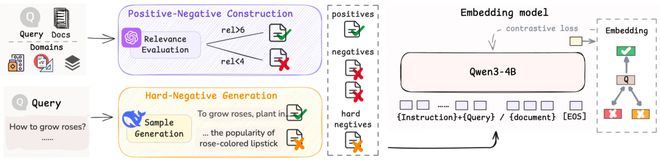
1. 合成的推理数据:在医疗诊断推导和数学定理证明等复杂推理领域,该技术团队构建了带有逻辑链标注的合成数据集。这些数据要求模型不仅要匹配关键词,更要学习隐含的逻辑关联性,如症状 - 病理的因果推断或数学命题的蕴涵关系。
2.「困难负样本」(Hard Negatives):训练中包含了大量与正确答案表面相似但实际错误的「陷阱」样本。这迫使模型不仅要看「像不像」,更要理解「是不是」,从而具备了极强的辨别能力。该技术团队设计了三级负样本筛选策略:
3. 基于难负样本采样的对比学习:通过引入对比学习框架,模型将正确答案与这些高难负样本同时进行对比训练。模型被迫聚焦于两者间微妙差异,从而提升了对复杂推理过程中的关键信息识别能力和鲁棒性。
通过这种方式训练出的检索器,能够精准地从海量信息中捕获到那些真正支撑推理链条的关键证据。
第四阶段:混合式重排序(Reranking)—— 确保最终答案的质量与连贯性
最后,初步检索出的文档列表会进入重排序阶段。DIVER 巧妙地结合了两种策略:逐点排序(Pointwise)策略和列表排序(Listwise)策略。这种「局部精调」与「全局统筹」相结合的混合模式,确保了呈现给用户的文档列表既有高质量的个体,又有最优的整体顺序。
技术突破验证
基准测评、行业对比、产业落地全面领先
BRIGHT 榜单达到 SOTA
DIVER 在权威的推理密集型检索基准 BRIGHT 上,其整体 nDCG@10(衡量前 10 个结果排序质量的指标)达到了45.8,全面超越了现有的其他具备推理能力的模型,达到了业界顶尖(SOTA)水平。
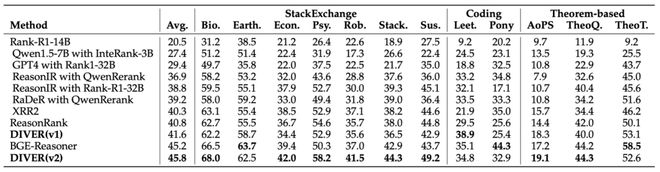

行业模型对比
在跨领域任务及不同查询难度的评测中,DIVER-Retriever 展现了显著的性能优势与强劲的泛化能力:在数学推理、通用科学和代码检索三大场景下,其 nDCG@10 与闭源模型 Seed1.5 Embedding相比,平均提升 2 个百分点;相较于参数规模为其两倍的开源模型 ReasonIR-8B,平均提升了 4 个百分点,充分验证了 DIVER-Retriever 在不同领域与难度条件下均能保持稳健而有效的检索性能。
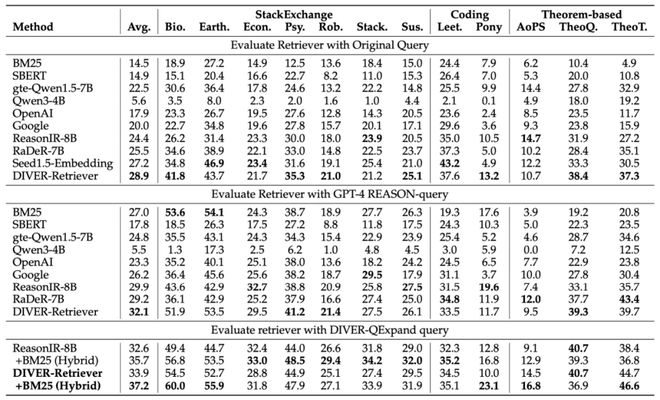
AQ 落地应用
医疗领域对知识的准确性和推理的严谨性有着极高的要求,尤其是在精准医疗的发展趋势下,必须根据患者的具体情况和医学原理制定治疗方案,而不能简单地照搬经验。
自 6 月在 AQ 医疗应用上线以来,DIVER 驱动的检索增强系统实现了临床级检索和循证精准突破:在诊疗证据召回场景中,相比 BGE-M3 模型,英文文献召回的 Hit@1 提升 11 个百分点;中文召回的 Hit@1 从 0.824 提升至 0.922,提升 9.8 个百分点;混合检索(中文召回英文)的 Hit@1 提升 8.6 个百分点。
同时 DIVER-Dchunk 应用在离线指南与论文的 chunking 环节,大幅提升了指南与论文检索信息的有效性。
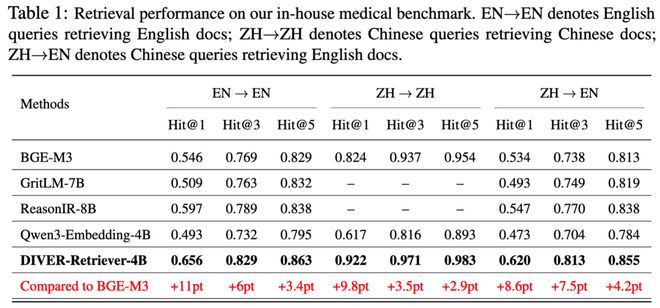
展望
蚂蚁 MedAI 将持续深耕复杂推理型的检索技术以及重排序技术,持续提升在医疗复杂推理、泛健康场景的检索循证能力。该技术团队将持续优化 DIVER 框架,为临床决策提供了可验证、可追溯、可更新的知识基础设施,重新定义医疗级 RAG 的技术标准。
接下来,该技术团队会陆续开源其他 size 的检索模型以及重排序模型,欢迎研究者与开发者关注并使用他们的模型,期待与更多科研机构及产业伙伴合作,共建开放繁荣的开源生态,共同推动人工智能与医疗 AI 的发展。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板