国庆长假在即,Deepseek又放大招了!
9月29日,DeepSeek-V3.2-Exp模型正式在Hugging Face平台发布并开源。
该版本作为迈向下一代架构的重要中间步骤,在 V3.1-Terminus 的基础上引入了团队自研的 DeepSeek Sparse Attention (DSA) 稀疏注意力机制,旨在对长文本的训练和推理效率进行探索性优化与验证,这种架构能够降低计算资源消耗并提升模型推理效率。
目前,华为云已完成对 DeepSeek-V3.2-Exp模型的适配工作,最大可支持160K长序列上下文长度。


核心技术突破:DeepSeek Sparse Attention (DSA)
DeepSeek Sparse Attention(DSA)首次实现了细粒度稀疏注意力机制。DeepSeek 方面表示,这项技术在几乎不影响模型输出效果的前提下,大幅提升了长文本场景下的训练和推理效率。
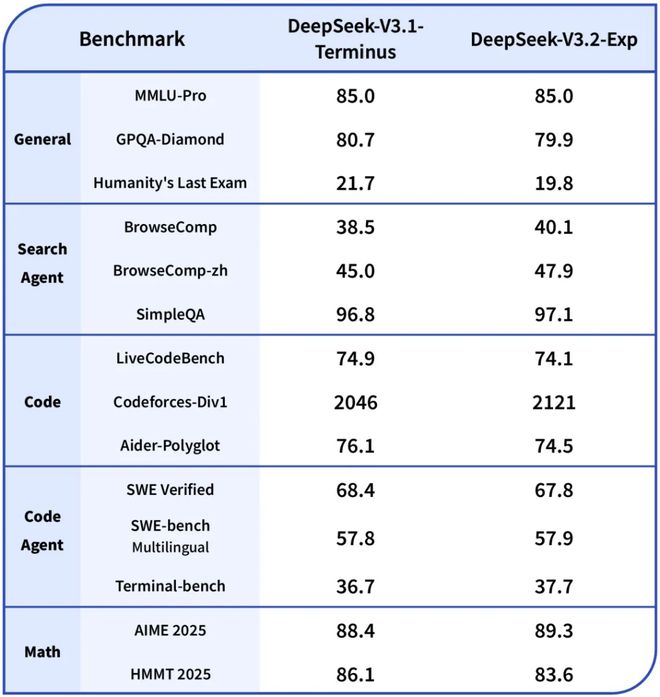
为了确保评估的严谨性,DeepSeek-V3.2-Exp 的训练设置与前代 V3.1-Terminus 进行了严格对齐。测试结果显示,该模型在各大公开评测集上的表现与 V3.1-Terminus 基本持平,有效性得到了初步验证。

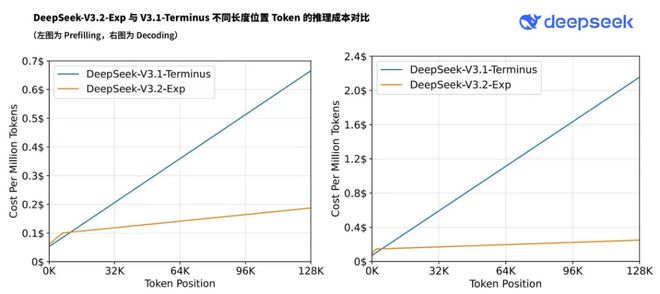
API成本将降低50%以上
随着新模型服务成本的显著降低,DeepSeek 同步采取了重磅举措:大幅下调官方 API 价格,降价幅度超过 50%,新价格已即刻生效。目前,官方 App、网页端和小程序均已同步更新至 DeepSeek-V3.2-Exp 版本。

DeepSeek 现已将 DeepSeek-V3.2-Exp 模型在 Huggingface 和 ModelScope 平台上全面开源,相关论文也已同步公开。
作为一款实验性版本,DeepSeek 认识到模型仍需在更广泛的用户真实场景中进行大规模测试。为便于开发者进行效果对比,DeepSeek 为 V3.1-Terminus 版本临时保留了 API 访问接口,且调用价格与 V3.2-Exp 保持一致。该对比接口将保留至北京时间 2025 年 10 月 15 日 23:59。
此外,为支持社区研究,DeepSeek 还开源了新模型研究中设计和实现的 GPU 算子,包括 TileLang 和 CUDA 两种版本。团队建议社区在进行研究性实验时,优先使用基于 TileLang 的版本,以便于调试和快速迭代。
⭐星标华尔街见闻,好内容不错过⭐
本文不构成个人投资建议,不代表平台观点,市场有风险,投资需谨慎,请独立判断和决策。
觉得好看,请点“在看”
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板