
DeepSeek在“省钱”和“省资源”上达到了变态的程度。
作者 | 许有阳
来源 | 盒饭财经(ID:daxiongfan)
头图及封面来源 | 网络及即梦制作
DeepSeek-V4总算来了。
4月24日,DeepSeek官方账号发布了一篇名为《DeepSeek-V4 预览版:迈入百万上下文普惠时代》的文章。文章中正式宣布,“全新系列模型 DeepSeek-V4 的预览版本正式上线并同步开源。”
同时,还介绍:DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。模型按大小分为两个版本:

发布后,测评、讨论已非常充分,不再赘述。
盒饭财经关注到,DeepSeek同步发布了一篇关于DeepSeek-V4 技术报告。地址如下:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
这份名为《DeepSeek-V4:Towards Highly Efficient Million-Token Context Intelligence》的技术报告,共55页,从架构、通用基础设施、预训练、训练后等6个部分介绍了V4。而这份高度专业的技术报告中,隐藏了10个有意思的小彩蛋。
彩蛋一:“Think Max”模式,绝不允许走捷径的“压榨”指令
位置:第30页,Table 3

原文为:
Reasoning Effort: Absolute maximum with no shortcuts permitted. You MUST be very thorough in your thinking... rigorously stress-testing your logic against all potential paths, edge cases, and adversarial scenarios.
翻译过来,大概的意思就是:
推理投入度:绝对最大化,不容许任何捷径。你的思考必须极其彻底,全面拆解问题以触及根本原因,并针对所有可能的路径、边缘案例及对抗性场景,对你的逻辑进行严苛的压力测试。要明确写出完整的深思过程,记录每一个中间步骤、考虑过的替代方案以及被否决的假设,确保绝对没有任何未经审视的预设。
这段话是模型开启 Think Max(极致思考模式)时,后台偷偷塞给大模型的“系统提示词(System Prompt)”。写得极具压迫感,像是一个严厉的导师在逼学生榨干脑力,不准有任何偷懒。
DeepSeek为其式设定了一套极为严苛的系统提示词。用词极具压迫感,还全部使用了绝对祈使句:“绝对最大化”“不许走捷径”“必须彻底”“严酷地压力测试”“不放过任何一个假设”。它还显式地命令模型“禁止走捷径”,要求记录每一个被拒绝的假设和中间步骤。
通过这种极度严厉的工程化Prompt,榨干大模型在 1M Context(百万上下文)里的算力去验证代码和逻辑错误。这就像是给模型戴上了“逻辑紧箍咒”,确保在处理复杂逻辑或代码时,模型不会因为追求速度而忽略细节。
彩蛋二:给硬件厂商的“公开信”:别瞎忙活带宽了
位置:第16页,Section 3.1

原文为:
Once bandwidth meets this threshold, it ceases to be the bottleneck, and devoting additional silicon area to further bandwidth brings diminishing returns. We encourage future hardware designs to target such balance points rather than scale bandwidth unconditionally.
意思是:
一旦带宽达到该阈值,便不再是瓶颈,此时将更多的芯片面积用于进一步提升带宽,会带来边际收益递减。我们鼓励未来的硬件设计瞄准这样的平衡点,而非一味地无条件扩展带宽。
DeepSeek在报告中反客为主,给英伟达和华为等硬件厂商开出了“方子”。体面表达了他们在硬件方面的观点:盲目提升带宽对现在的AI训练效率提升有限,建议厂商把芯片面积留给更能提高计算通信比的地方。
彩蛋三:极致效率,1M长度下仅需V3.2的10%缓存
位置:摘要,Abstract

原文:
In the one-million-token context setting, DeepSeekV4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2.
意思是:
在百万级token上下文设定下,与DeepSeek-V3.2相比,DeepSeek-V4-Pro仅需其27%的单token推理FLOPs,以及10%的KV缓存。
DeepSeek在“省钱”和“省资源”上达到了变态的程度。
通过 CSA(压缩稀疏注意力)和 HCA(重度压缩注意力)技术,它在处理100万字的长文本时,占用的内存竟然只有前代版本的十分之一。这意味着未来个人电脑甚至手机运行百万超长文本分析将成为可能。
彩蛋四:坦诚的“炼丹玄学”:知其然不知其所以然
位置:第26页,Section 4.2.3

原文为:
Although a comprehensive theoretical understanding of their underlying mechanisms remains an open question for now, we are sharing them openly to foster further exploration by the community.
意思是:尽管目前对其底层机制的全面理论理解仍是一个悬而未决的问题,但我们将其公开分享,以推动社区的进一步探索。
在Mitigating Training Instability 缓解训练不稳定性章节中,DeepSeek团队分享了两个解决万亿参数模型训练崩溃的独门绝技,Anticipatory Routing和SwiGLU Clamping。
技术报告中,他们也非常耿直地承认:这种“虽然我不知道原理是啥,但它跑起来确实有用,大家拿去用吧”的坦诚,可以说是AI炼丹界的真实写照了,非常有开源精神。
彩蛋五:“快指令”(Quick Instruction)特供Token
位置:第33页,Table 5
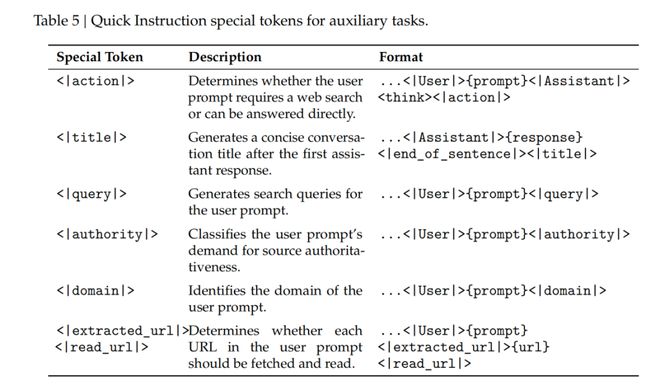
<|action|> (判断是否搜网), <|title|> (生成标题), <|query|> (生成搜索词)。
为了让Chatbot响应更快,DeepSeek在模型内部植入了一系列专用Token“暗号”。
V4之所以能这么快,是因为它直接复用了已经算好的长文本 KV Cache(缓存)。不用像以前那样把几十万字重新喂给另一个小模型去判断,从而彻底消除了“冗余的预填充(redundant prefilling)”,这样用户的等待时间就能大幅缩短。
彩蛋六:Codeforces全球排名第23位
位置:第39页,Section 5.3.2

原文为:On the Codeforces leaderboard, DeepSeek-V4-Pro-Max currently ranks 23rd among human candidates.
这句话的意思是,在 Codeforces 排行榜上,DeepSeek-V4-Pro-Max 当前在人类参赛者中位列第23名。
这个“彩蛋”极具含金量。在纯人类参与的全球顶级编程竞赛Codeforces排名中,DeepSeek-V4的预估分值(3206分)足以排到全球第23名。这意味着它已经超越了绝大多数顶级程序员,进入了人类编程智力的最顶端一小撮。
彩蛋七:内部“员工大调查”,52%的人已离不开它
位置:第44页,Section 5.4.4

原文为:
In a survey asking DeepSeek developers and researchers (= 85) — all with experience of using DeepSeek-V4-Pro for agentic coding in their daily work— whether DeepSeek-V4-Pro is ready to serve as their default and primary coding model compared to other frontier models, 52% said yes, 39% leaned toward yes, and fewer than 9% said no.
翻译过来是:
在一项面向DeepSeek开发者和研究人员的调查(N=85)中,这些受访者均有在日常工作中使用DeepSeek-V4-Pro进行智能体编码的经验。当被问及与其他前沿模型相比,DeepSeek-V4-Pro是否已准备好成为他们默认且主要的编程模型时,52%给出了肯定回答,39%倾向于肯定,而表示否定的不足9%。
DeepSeek非常罕见地公开了公司内部85名顶尖研究员的真实反馈。超过一半的DeepSeek内部核心人员已经将其作为日常首选编程工具。这种“吃自己的狗粮”的行为比跑分数据更能说明模型在实际生产中的情况。
彩蛋八:内部员工的真实“吐槽”被写进技术报告
位置:第44页,Section 5.4.4

原文:
Respondents find DeepSeek-V4-Pro to deliver satisfactory results across most tasks, but note trivial mistakes, misinterpretation of vague prompts, and occasional over-thinking.
翻译过来就是:
受访者认为DeepSeek-V4-Pro在大多数任务上都能给出令人满意的结果,但也指出它存在一些细小的错误、对模糊提示的理解偏差,以及偶尔的过度思考。
这句话紧挨着上一条“内部员工调查”的彩蛋,DeepSeek选择把内部员工的吐槽也写了进去。
彩蛋九:接地气的“中国特色”评测题
位置:第43页,Figure 13

为了展示模型在复杂长文本白领工作中的能力,DeepSeek放出的示例任务非常接地气。
“写一份某知名奶茶品牌与北京地铁的联名营销策划”“UGC传播与社交裂变设计”,比起国外大模型测写全英文的莎士比亚诗歌,DeepSeek的评测题真的很懂国内打工人的日常PPT需求。
彩蛋十:致谢名单里的神秘测试Dolly Deng
位置:第55页,附录 A.2 致谢部分

附录 A.2 致谢(Acknowledgment)部分,除了全体作者外,团队特别单独点名感谢了一位非作者人士:“We would like to thank Dolly Deng and other testers for their valuable suggestions and feedback...”
翻译过来就是,我们要感谢 Dolly Deng 及其他测试人员,就DeepSeek-V4系列模型的能力所提出的宝贵建议与反馈。
能在这样一份AI基础模型技术报告中被单独拎出来感谢的测试(或外部反馈者),不知道他在V4内测期间提交了怎样关键的Bug或改进建议。
欢迎在评论区留言~如需开白请加微信:YPYP01234567
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板