
当地时间 5 月 5 日,迈阿密一家名为 Subquadratic 的公司走出隐身模式。CTO Alexander Whedon 在 X 上把首款模型 SubQ 称作“a major breakthrough in LLM intelligence”(LLM 智能领域的重大突破),声称这是首个完全基于次平方稀疏注意力(Subquadratic Sparse Attention,SSA)架构的前沿模型,1,200 万 token 上下文,1M token 场景下比 FlashAttention 快 52 倍,成本不到 Claude Opus 的 5%。同日宣布完成 2,900 万美元种子轮,估值 5 亿美元。
融资由 Tinder 联合创始人 Justin Mateen 旗下 JAM Fund 与前软银愿景基金合伙人 Javier Villamizar 领投,参投方包括 Anthropic、OpenAI、Stripe、Brex 的早期投资人。CEO Justin Dangel 是连续创业者,履历集中在健康科技、保险科技和消费品。
CTO Alex Whedon 此前在 Meta 担任软件工程师,之后在咨询公司 TribeAI 出任 Head of Generative AI。官网称团队还有 11 名来自 Meta、Google、牛津、剑桥、字节跳动、Adobe的 PhD,姓名未公开。

图丨相关推文(来源:X)
按官方文档,SubQ 要解决的是 Transformer 最根深蒂固的那道天花板:注意力机制的算力消耗随上下文长度呈平方级增长,序列翻一倍,算力翻四倍。
Subquadratic 把这种 dense attention 视作根本性的成本瓶颈,自家方案命名为 SSA。其核心机制按报告原文是 content-dependent selection,对每个 query,模型选出“值得 attend 的位置”,只对那些位置做精确的 attention 计算。博文同时把 SSA 总结为三项独有优势:在计算和内存上都是线性扩展、内容相关的路由、可以从任意位置稀疏检索。
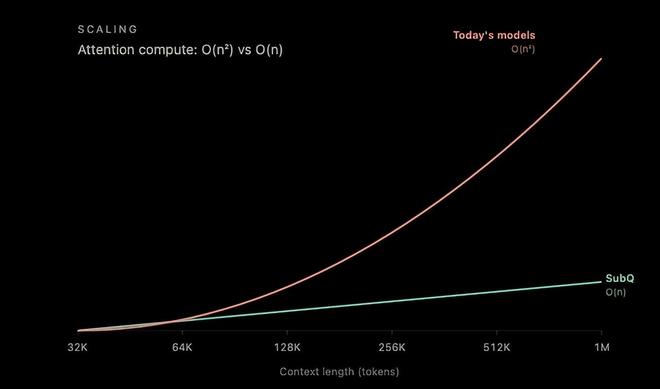
图丨注意力计算量(来源:Subquadratic)
据官方披露,在 B200 GPU 上对比 FlashAttention-2,128K token 时 SubQ 快 7.2 倍,256K 时 13.2 倍,512K 时 23 倍,到 1M token 时拉到 52.2 倍。按官方推算,序列长到 12M token 时,注意力计算量比标准 dense attention 减少近 1,000 倍。
Benchmark 也直接对位主流前沿模型。RULER 128K 长上下文测试上 SubQ 拿到 95.0%,与 Claude Opus 4.6 的 94.8% 几乎打平。SWE-Bench Verified 上 81.8%,超过 Opus 4.6 的 80.8% 和 Gemini 3.1 Pro 的 80.6%。
在考察长上下文多源证据检索整合能力、也是最关键的 MRCR v2 上,SubQ 同时报了两个分数,研究版 83,第三方验证的生产版 65.9。同项目下 Claude Opus 4.7 是 32.2,Gemini 3.1 Pro 26.3,GPT 5.5 74.0。
如此逆天的数据自然引发了大量关注,质疑也随之而来。
前 OpenAI Sora 团队成员、AI 工程师 Will Depue 第一时间发出质疑:SubQ 几乎可以肯定是对 Kimi 或 DeepSeek 稀疏注意力(sparse attention)的微调。Whedon 几个小时后的帖子部分证实了这一推测,公司确实将开源模型的权重作为起点,“这是基于我们目前的资金规模和公司发展阶段做出的选择”。

图丨相关推文(来源:X)
但回看此前的相关研究,Kimi Linear 实际是混合结构,3/4 的层用线性注意力,剩下 1/4 仍然用平方复杂度的 MLA,Kimi 自己在论文里就承认纯线性版本 “在精确记忆检索和精确复制上仍然吃力”,所以没有用在所有层。
DeepSeek Sparse Attention 内部负责筛选 token 的 lightning indexer 自身仍是 O(n²),只是常数因子比 MLA 小一个数量级,复杂度被搬了位置而已。Mamba 和 RWKV 在 FLOP 层面确实做到了线性,但在前沿规模下游任务上跑不过标准注意力,至今没有任何前沿 LLM 单独使用它们。
如果 SubQ 把权重起点放在这些已经被业界明确画出复杂度边界的方案上,又是怎么在它们的基础上做出“减少 1,000 倍计算量”这种数量级跃升的?
清华大学交叉信息研究院博士游嘉诚也在 X 上提到,Subquadratic 所宣称的计算和内存上都是线性扩展这个特性实际上并不是 SSA 独有。dense attention 配合 FlashAttention 早已做到线性内存,这是业界几年前就普及的标配,SubQ 却依然把它单列为 SSA 三大独有优势之一来宣传。
按照官方博文的说法,SSA 的核心不是对 attention 做近似,而是不再假设每一对 token 都可能重要,把计算只限制在真正承载信号的位置上,跳过其余。
那么问题来了,模型如何在跑 attention 之前知道哪些位置承载信号?这本身是个循环:要判断某个 token 没有信号,就必须先把它和当前 query 比较一次,而比较本身的代价正是 quadratic 的全部来源。
Will Depue 用 phonebook eval 解释了这件事。phonebook 是衡量长上下文检索能力的一种基准,给模型一份 10 万人的电话簿,再问其中某个特定姓名的电话。模型不知道未来会被问到哪个姓名,理论上必须保留所有姓名在 context 里。任何 “提前丢弃信息” 的策略,在这个 eval 上都会失分。
博文里没有解释 SSA 的 selection 机制如何解决这个循环。一种可能是 SSA 内部有一个轻量 indexer 做评分(类似 DSA),但 selector 自身仍是 O(n²),复杂度只是被搬了位置。另一种可能是 selector 使用某种 learned gating,从训练数据中学到哪些位置值得保留,但这种方案在 phonebook 这类 “信息位置完全不可预测” 的任务上几乎注定失败。
报告称,训练数据特意选用“信息密度高、交叉引用结构丰富的长文本”,因为这类数据“会迫使 selection 机制学会跨越大跨度位置做路由”。这相当于承认 selection 机制是被训练出来的,而不是从 attention 矩阵动态推导出来的。一旦 selection 是 learned gating,长上下文检索的可靠性就被锁死在训练数据的分布里:训练数据里见过的位置和模式,模型能找到;分布之外的,比如 phonebook 这种全然随机的查询,模型只能赌。
官方公布的 benchmark 同样疑点重重。最大卖点 12M token 并没有完整 benchmark,所有 RULER、MRCR v2、SWE-Bench 的成绩都来自 1M-Preview 版本,“12M token 上的研究结果” 对应的只是一个 92.1% 的 needle-in-a-haystack 分数,而这是长上下文测试里最简单的一种,只考察模型能否在大堆 token 里找到一根特定的针,不评估多跳检索或证据整合。
但它是不是骗局终究还无法实锤。Subquadratic 尚未公布详细模型卡,目前只能通过申请小范围内测来试用,独立基准测试结果也还没有出来。
不过说起来,类似的剧本两年前刚上演过一次。
2024 年 8 月,旧金山公司 Magic.dev 发布 LTM-2-mini,宣称 1 亿 token 上下文窗口、相对标准注意力 1,000 倍效率优势,凭这一发布累计融资超过 5 亿美元。到 2026 年初,没有任何 Magic 之外的开发者或企业公开使用 LTM-2-mini 的记录,技术报告没出,模型没开源,benchmark 也没有第三方复现。
SubQ 的发布材料和 Magic 当年高度同构,同样的 1,000 倍效率,同样 “打破 Transformer 平方律” 的叙事,同样不开源,同样把完整技术细节推迟到 “完整模型卡片即将公布”。差别是 SubQ 这次一上来就奔着商业化产品去(API、CLI agent、搜索),而 Magic 当年还停留在研究 demo 阶段。
因此,它的成色究竟如何,或许能比 Magic.dev 更快见分晓。
参考资料:
1.https://subq.ai/introducing-subq
2.https://venturebeat.com/technology/miami-startup-subquadratic-claims-1-000x-ai-efficiency-gain-with-subq-model-researchers-demand-independent-proof
3.https://x.com/willdepue/status/2051734355509235734
运营/排版:何晨龙
注:封面/首图由 AI 辅助生成
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板