
机器之心发布
当推荐系统遇上大模型范式,广告变现的天花板被再次打破。快手提出 GR4AD,作为国内生成式推荐在大规模广告场景下的首次全量落地,实现广告收入提升 4.2%,服务 4 亿 + 用户。

论文链接:https://arxiv.org/pdf/2602.22732
一、引言:"推荐该怎么做" 的新范式
过去十年,深度学习推荐模型(DLRM)几乎统治了整个工业界的推荐系统 —— 从召回到排序,从特征交叉到序列建模,它们构建了一套成熟而稳固的技术栈。然而,当大语言模型(LLM)的浪潮席卷而来,一个大胆的问题被抛了出来:
能不能像生成文本一样,直接 "生成" 推荐结果?
这就是生成式推荐(Generative Recommendation)的核心思想。以 TIGER、OneRec 为代表的一系列工作,已经在自然推荐场景中验证了这一范式的可行性。但当战场转移到大规模广告系统—— 这个对时延、收益、商业价值都有极致要求的领域 —— 事情变得远没有那么直接。
快手的这篇论文,正是对这一问题交出的一份沉甸甸的工业级答卷。他们提出了GR4AD(Generative Recommendation for ADvertising),一个横跨表征、学习、服务三大层面协同设计的生成式广告推荐系统,并已全量部署于快手广告平台,服务超过 4 亿用户
二、问题与挑战:广告场景下的三大挑战
论文开篇就旗帜鲜明地指出:直接把 LLM 那套训练和推理范式搬到广告推荐上,是行不通的。 具体来说,广告场景存在三个独有的核心挑战:
挑战一:广告物料的 Token 化 —— 多元信息的统一编码
广告不是普通的短视频。一条广告背后融合了视频创意、商品详情、广告主 B 端元数据等多模态、多粒度信息。更棘手的是,平台还提供了转化类型、广告账户等关键业务信号,这些信号具备强烈的商业价值但几乎没有 "语义内容" 可言。如何为广告物料打造一套既能捕获语义内容、又能编码业务信息的统一 Token 体系
挑战二:学习范式 —— 面向商业价值的列表级优化
广告推荐的优化目标不是 "猜中用户会点哪个" 那么简单,而是要在eCPM 排序、NDCG 等列表级指标下最大化商业价值。现有的生成式推荐方法大多沿用 LLM 的分阶段训练方式,不完全适配大规模推荐场景的持续在线学习,且缺乏面向排序的、列表级的学习设计。
挑战三:实时服务 —— 多候选生成的算力困局
不同于 LLM 聊天场景中 "解码一条回复、容忍较长延迟" 的模式,广告系统需要在极高 QPS 和极低延迟(<100ms)下,通过 Beam Search同时生成大量高质量候选。这是一个与 LLM 不同的推理优化问题。
三、方法:全链路协同设计的破局之道
GR4AD 的方法论可以用一句话概括:"表征 - 学习 - 推理" 三位一体的推荐原生设计。 下面逐一拆解。
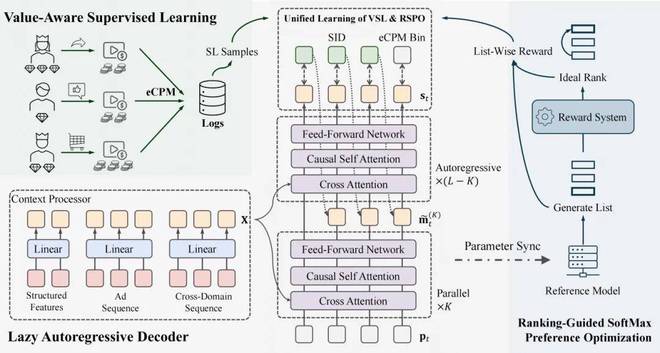
3.1 统一广告语义 ID(UA-SID):给广告一个 "身份证"
核心思想:用一个端到端微调的多模态大模型(MLLM)为每条广告生成统一嵌入,再通过精心设计的量化方法将其编码为离散 Semantic ID。
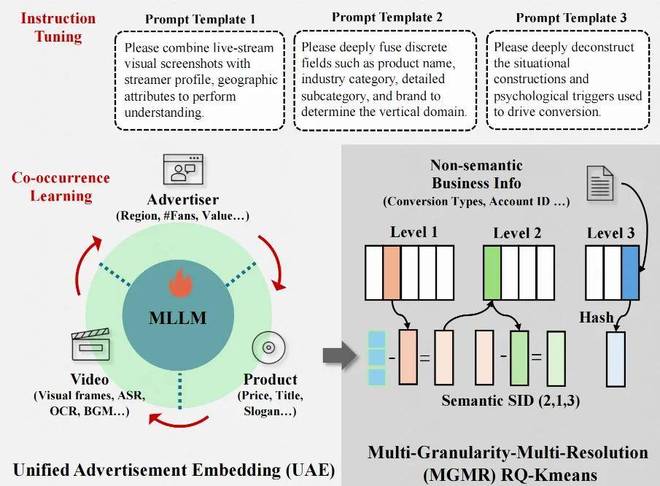
第一步:统一广告嵌入(UAE)
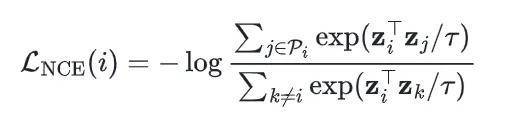
第二步:MGMR RQ-Kmeans 量化
这是 UA-SID 的 "杀手锏"。论文提出了多粒度 - 多分辨率(Multi-Granularity-Multi-Resolution)的 RQ-Kmeans 量化策略:
最终每个广告物料被映射为一个离散 UA-SID 序列:
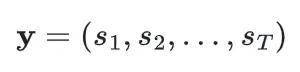
3.2 LazyAR:懒惰解码器的大智慧
生成式推荐在推理时需要通过 Beam Search 生成多个候选 SID 序列。标准自回归解码要求每一层都依赖上一步的输出,这在 Beam 数很大时造成了巨大的计算瓶颈。
论文的一个关键观察是:第一层 SID 最难学、损失最大,但它的 Beam 只有 1(从 BOS 开始);后续层级更容易,Beam 却呈指数级膨胀。 大部分计算被浪费在了 "简单的事情" 上。
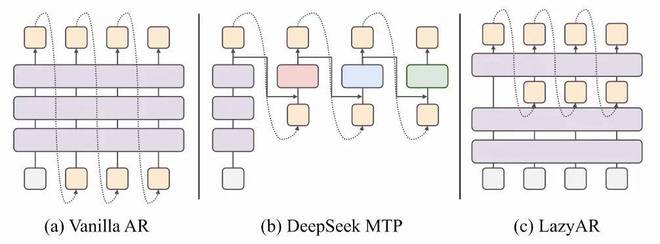
LazyAR 的核心操作: 将对上一步 token 的依赖 "延迟" 到中间某一层(第 K 层)注入:
为什么 LazyAR 有效?
1. 第一层 SID 的解码过程完全不受影响(从 BOS 经过全部 L 层)。
2. 前 K 层在潜空间中进行推理,能编码关于候选 token 的有用信号。
3. 引入 MTP 辅助损失,强制前 K 层即使没有上一步 token 也能学到足够信息。

论文特别指出:这个设计是推荐原生的,不适用于标准 LLM 解码 —— 因为 LLM 解码通常不用 Beam Search,且后续 token 的预测难度不一定下降。
3.3 价值感知的监督学习(VSL)
在广告场景中,不同样本的商业价值天差地别。VSL 围绕 "价值感知" 做了三件事:
①SID + eCPM 联合预测: 在标准 SID 交叉熵损失之外,将 eCPM 离散化为桶并追加为额外的预测 token:
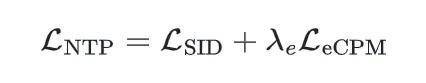
②价值感知样本加权: 每个样本的权重 ,高广告价值用户和深度交互行为(如购买)获得更高权重。
![]()
③MTP 辅助损失: 配合 LazyAR,强制前 K 层并行解码的表征质量。
最终 VSL 目标:

3.4 排序引导的强化学习(RSPO):从 "学分布" 到 "优排序"
VSL 能拟合历史数据分布,但它不直接优化下游排序目标,也不支持对未知标签分布的探索。论文因此引入了 RSPO(Ranking-Guided Softmax Preference Optimization),一个面向列表级 NDCG 优化的 RL 算法
RSPO 的核心 loss
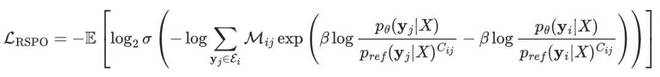

几个精妙的工程设计:

四、线上部署:工业级系统的全闭环设计
GR4AD(0.16B 参数)已全量部署于快手广告系统,实现了一套 “奖励估计 → 在线学习 → 实时索引 → 实时服务” 的完整闭环。
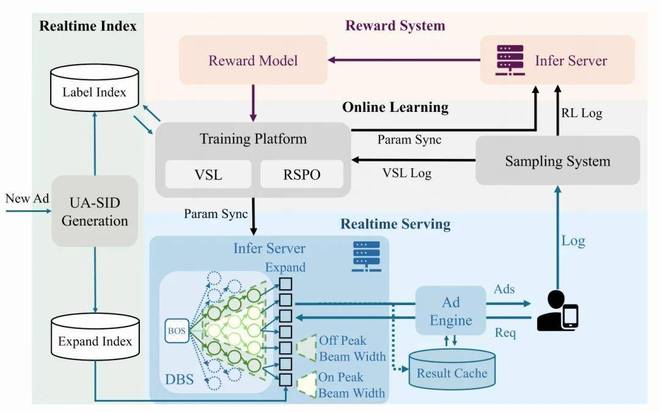
4.1 四大核心模块
4.2 推理效率优化:把算力用在刀刃上
动态 Beam 服务(DBS)是本文的又一亮点,包含两个子机制:
此外还有一系列工程优化:Beam 共享 KV Cache:将 Beam 从 batch 维度转移至序列维度进行组织,实现 KV Cache 的共享,显著提升内存访问效率(+212.5% QPS)、TopK 预裁剪:先并行选取每个 Beam 的 K 个候选结果,再对聚合候选集进行全局 Top-K 选择,在有效缩减搜索空间的同时保证准确性(+184.8% QPS)、FP8 低精度推理(+50.3% QPS)、短 TTL 结果缓存(+27.8% QPS)。
最终效果:<100ms 延迟,500+ QPS/L20 GPU
五、实验效果:广告收入和推理性能的双赢
5.1 总体性能与消融实验
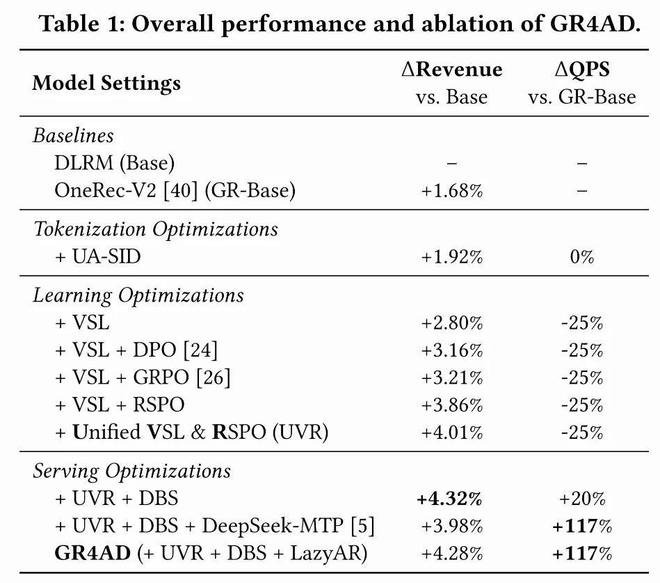
几个关键发现:
5.2 Scaling Law
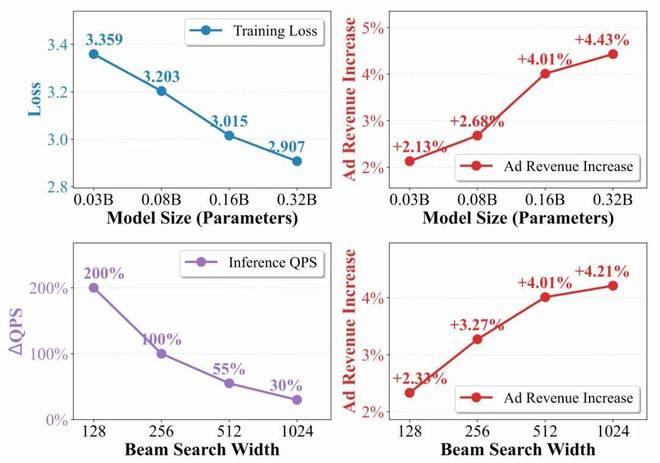
模型规模方向:从 0.03B 到 0.32B,收入提升从 + 2.13% 单调增长到 + 4.43%,训练损失也持续下降。生成式广告推荐的 Scaling Law 是成立的
推理规模方向:Beam 宽度从 128 增加到 1024,收入从 + 2.33% 提升到 + 4.21%。这意味着更强的推理时搜索能进一步释放模型潜力—— 这与当前 LLM 领域 Test-time Scaling 的趋势遥相呼应。
5.3 UA-SID 质量
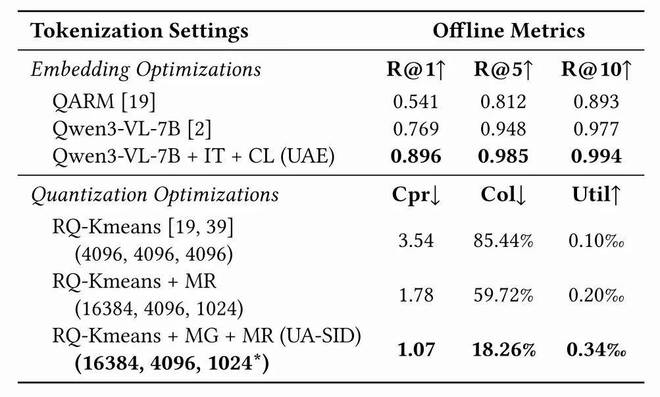
在嵌入质量评估(photo-to-photo recall)中,经过指令微调和共现学习的 UAE 达到了 R@1=0.896,远超基线 QARM(0.541)和原始 Qwen3-VL-7B(0.769)。MGMR 量化将 SID 碰撞率从 85.44% 降至 18.26%,码本利用率提升 3 倍以上。
5.4 商业指标的全面胜利
基于内容的 SID 带来的更强泛化能力和更实时的索引对冷启动物料的更好支持,实现了平台、广告主、用户的三赢
六、总结与思考
GR4AD 这篇论文的价值,不仅在于它达成了 4.2% 的收入提升这个数字,更在于它系统性地回答了一个关键问题:生成式推荐在广告这个最 "硬核" 的工业场景中,到底应该怎么做?
它的答案是:不要照搬 LLM,要做推荐原生的设计
GR4AD 是生成式推荐走向广告工业核心场景的一个重要里程碑。 快手用超过 4 亿用户的真实流量验证了这条路径的可行性。可以预见,接下来会有更多广告平台跟进这一范式。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板